

ARM 的崛起构筑了终端市场的繁荣,也终结了 x86 过去 40 余年一家独大的局面。随着 ARM 构架开始更多的向 x86 设备中渗透,越来越多的服务也转向了 ARM 云平台。华为公司作为 ARM 服务器市场的先行者,其自研的鲲鹏系列 ARM 处理器,性能处于 ARM 平台服务器 CPU 的第一梯队。秉持着“硬件开放、软件开源、使能伙伴”的初心,鲲鹏产业生态正在赋能更多的行业,也吸引了成千上万开发者的关注和参与,优秀的开源项目和应用实践不断涌现。
凭借自身雄厚的技术实力和研发经验,华为联合各地鲲鹏生态创新中心在全国范围内开启了鲲鹏应用创新大赛 2020,本次大赛设置有十三大赛区,广州赛区便是其中之一。7 月 25 日,广州鲲鹏生态创新中心以线上直播方式举办的【鲲鹏应用创新大赛 2020·广州赛区宣讲会】成功召开。本次活动不仅邀请到了华为鲲鹏资深技术专家为开发者全方位讲解鲲鹏软件迁移和性能调优技术,还在线解答了关于本次大赛的相关问题,帮助开发者更多了解到广州赛区的赛事详情。
以下内容经由 InfoQ 编辑整理自鲲鹏创新应用大赛 2020 广州赛区宣讲会速记。
为什么要进行软件迁移、怎么迁移?
x86 和华为鲲鹏 ARM 架构之间最大的区别源自于指令集的不同。以下图的 C/C++ 程序代码中的“c=a+b”语句为例,我们可以看到其通过编译器编译汇编指令后,指令集存在以下三点差异:
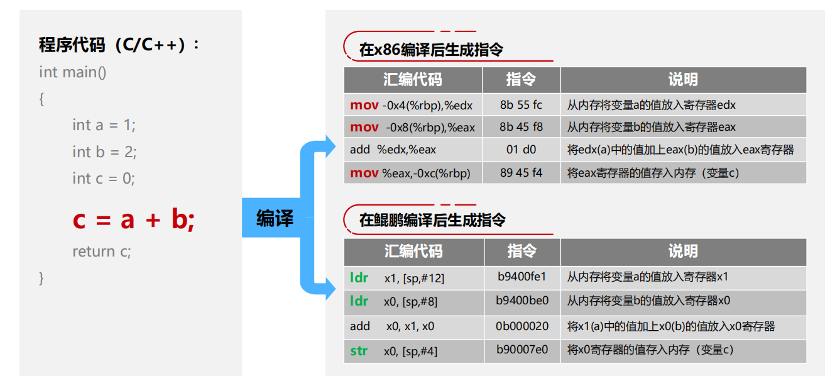
1、汇编不同:语句在 x86 平台下生成一个汇编指令后,通过 3 条 mov 指令和 1 条 add 指令完成执行;而鲲鹏处理器则是通过 ldr 指令将数据加载到计算器当中,再通过 add 指令将两个计算器里面的数据进行相加,最后通再过一条 Str 指令将计算器中的内容存储在内存当中。
2、指令长度不同:x86 上 mov 指令是 24 位的,ldr 指令是 16 位的;而鲲鹏处理器的指令是定长的 32 位指令。
3、寄存器不同:x86 和鲲鹏处理器使用的向量寄存器不同,其向量指令级也存在差异。
基于上述的指令集差异,因此基于 x86 平台编译生成的应用程序,在鲲鹏处理器平台上进行运行的时候,需要进行重新的编译。
那么,从 x86 到鲲鹏的软件迁移如何操作?鲲鹏在长期的项目迁移过程中总结了五大步骤:
1、迁移准备——收集硬件和软件栈信息,并准备编译环境。包括以芯片、服务器信息为主的硬件信息和中间件、编译器、业务软件、开源软件和商业软件等为主的软件栈信息。同时,进行编译环境的准备,可以通过申请 OpenLab 的软件帮助我们完成迁移。
2、迁移分析——分析软件栈制定迁移策略。软件技术栈分析主要分为业务软件分析和运行环境分析两大类。在业务软件中,开源软件可通过获取开源软件代码进行程序编译,或直接下载 ARM 上已编译好的软件包;自研软件则需根据语言类型差异制定不同的迁移策略;商用软件是鲲鹏处理器常用版本,当无法获取相应商用软件版本时,可通过其他软件或开源软件进行替换。运行环境、虚拟机、编译器和操作系统这些也是要进行替换,可以直接去软件仓库下载由鲲鹏官方验证的版本。
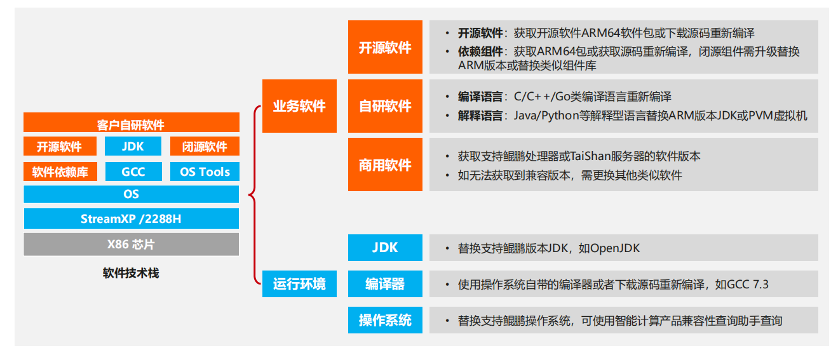
3、编译迁移——软件编译打包,验证基本功能。主要分为代码迁移和软件包迁移,代码迁移的过程中需要区分编译型语言和解释型语言;软件包迁移的核心在于 RPM 包的重构,包括扫描软件包的依赖项,对这些依赖库进行重新编译打包。
4、性能调优——完成迁移之后需要进行性能调优。这里总结出性能调优的五步法:首先是建立基准。根据当前硬件配置和测试模型,确定调优的目标。第二,压力测试。对测试系统进行压力测试,记录数据变化。第三,确定瓶颈。系统的瓶颈通常会在 CPU 过于繁忙、IO 等待、网络等待、响应时延等方面出现。第四,实施优化。重点观察系统资源的瓶颈,对瓶颈点实施进一步调优策略。第五,确认效果。重新启动压力测试,准备好相关的工具监视系统,确认优化效果。
5、测试与认证。对软件进行功能测试、性能测试、长稳测试,以确保达到鲲鹏规模商用的标准。
C/C++ 等编译型语言如何迁移?
C/C++ 作为典型的编译型语言,由于架构、指令集、向量寄存器的差异,程序在从 x86→鲲鹏处理器时,必须经过重新编译才能运行。
从代码工程的角度来看,C/C++ 的文件分为两类,一是编译构建的脚本,二是源码。其中:
1、编译构建脚本类文件在迁移过程中一般会涉及编译选项的移植,包括指定数据类型、生成代码特性、目标执行器架构、处理器硬件加速功能等。
2、源码文件的迁移,一般会涉及到编译宏的移植、编译器自带 builtin 函数移植、内联汇编移植、SSE intrinsic 函数移植等。
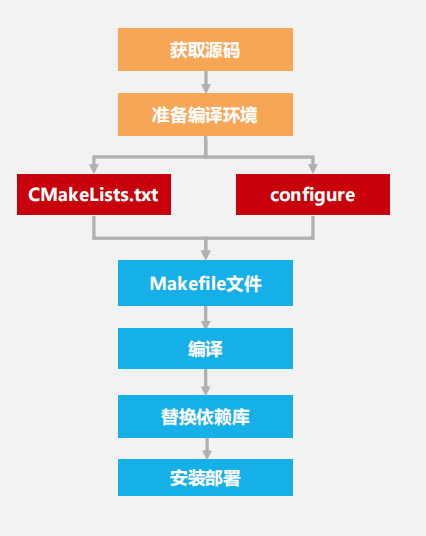
下图展示了 C/C++ 代码完整的编译构建过程。首先通过 GitHub 和第三方开源社区获取相应的源码。其次安装 gcc 版本,准备编译环境。之后使用源码中的 CMakeLists.txt 或 configure 脚本生成 makefile。随后执行 makefile 编译可执行程序,并替换依赖库。最后,将可执行程序安装部署到生产或测试系统。
不过,C/C++ 代码在迁移中也会有诸多问题存在,最具代表性的五类迁移问题如下:
1、编译脚本和编译选项的移植。不同的架构平台会有独特的编译选项支持硬件特性,与当前编译平台属性强相关这种带有架构属性的编译选项需要进行移植,这些编译选项一般以–m 开头;
2、编译宏的移植。编译宏的作用是确定平台下需要执行哪个分支代码,一般分为 x86 自定义宏和用户自定义的宏。两类宏的编译移植方式各不相同;
3、builtin 函数问题。builtin 函数是编译器自定义的函数,有较好的性能,可以实现一些简单快捷的功能,根据相应需求进行使用优化,助力程序编写;
4、内联汇编移植,常用迁移方法有汇编指令方式替换以及 builtin 函数替换两种;
5、SSE intrinsic 函数移植。一般在多媒体技术开发以及数学矩阵库中应用较多的 SSE intrinsic 函数移植较为复杂,为重难点。
Java/Python 等解释型语言怎么迁移?
Java 源码迁移的改动点一般有三个。第一是安装 JDK 改动点,第二是引用 SO 库的改动点,第三是程序运行时的改动点。
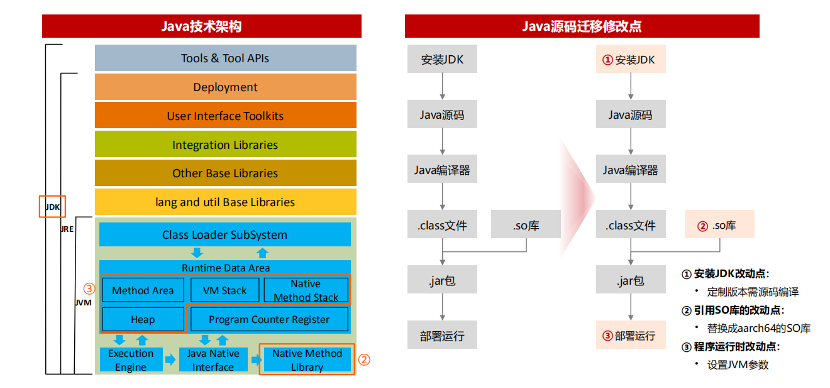
安装 JDK 改动点迁移方法
Java 源码移植过程首先需要安装合适的 JDK 版本。基于对环境稳定性等要求,最好安装一个稳定成熟高版本 JDK。因为一般新版本的 JDK 往往会增加一些特性使其变的更加方便和敏捷。目前鲲鹏上已经适配了 EDM 八版本的 JDK,不过,如果因为特殊的需求,需要安装某个特定版本的 JDK,则需要通过源码编译部署来实现。
那么,源码编译部署一个 JDK 应该如何来实现呢?首先需要安装一个 GCC,其次获取 JDK 源码,获取源码之后我们需要配置编译选项。例如配置语言选项、设置目标平台位数、忽略警告、调试等级等等。在完成编译选项后,可以执行 make all 进行编译。编译完成之后可以得到二级指文件,这个时候涉及环境变量进行验证,通过验证可以看到是不是我们想要的 Java 版本。
包含 SO 库调用的 jar 包迁移方法
首先通过 Dependency Advisor 工具分析扫描 jar 包,识别依赖 SO 库,并下载 SO 库源码。随后安装 maven、gcc,并设置参数。最后编译 SO 库和替换 SO 库,并重新打包 jar 文件,这样得到的 jar 包就可以在鲲鹏平台上运行。
设置 JVM 参数解决程序运行时改动点。
设置 JVM 参数可以保证程序能稳定、快速的运行。这里提供三大迁移经验和两大差异。
三大经验:首先,完成一次 Full GC 后,应该释放出 70% 的堆空间(30% 的空间仍然占用)。其次,假设老年代存活对象 (即 Full GC 后老年代内存占用) 大小为 X,建议堆的总大小是 X 的三到四倍,年轻代的大小是 X 的 1 到 1.5 倍,老年代的大小是 X 的两到三倍,永久代的大小是 X 的 1.2 到 1.5 倍。第三,JDK 官方的建议是年轻代大小占整个堆空间大小的 3/8 左右。
在具体的项目过程中,还会存在两大差异:第一,线程大小的 Xss 参数在 ARM 上默认值是 2m,在 x86 为 1m。因此如果线程开的太多,就需要调整 xss 参数大小,防止出现耗时。第二,由于 ARM 和 x86 指令集的差异性,导致 JDK 的 JIT 编译存在差异。可以通过设置参数 ReservedCodeCacheSize,调整 CodeCache 大小。
那么,Python 代码如何进行迁移呢?我们从 Python 源码迁移的改动点来看,分别是 Python 的版本改动点和引用 SO 库的改动。
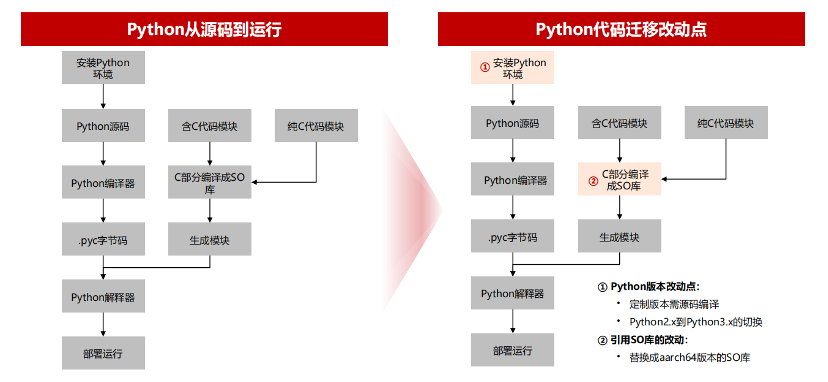
升级 Python 版本
目前 Python2X 版本官方已经停止维护了,因此建议把环境升级至 Python3X。首先,安装 GCC,配置编译选项 fsigned-char。随后在官方网站下载源码包并解压,配置编译选项。随后生成一个 Makeall 的文件,进行编译和安装。安装完成之后会在设定的安装目录得到 Python3 的二级指文件,可以看到 Python 显示版本号已经是我们想要的版本了,说明 Python 环境安装已经成功。
含 C 模块或全 C 模块的迁移
含 C 模块或全 C 模块的迁移,其核心是调用了 SO 库,对于 SO 库我们需要重新编译得到 aar64 的版本。首先,通过 Porting Advisoe 工具分析源码,识别依赖 SO 库和 C 代码。随后下载模块源码、安装 GCC 并配置 -fsigned-char 选项。之后执行 setup 自动完成模块编译。编译完成之后,自动会完成 aacrh64 版本库的替换,然后我们将编译完成得到的模块安装到 site—packages 目录下,供其他 Python 源码调用。
软件调优怎么做?
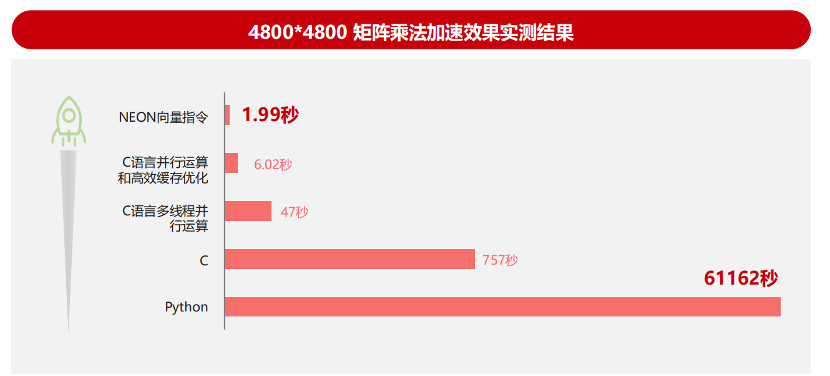
软件性能调优是开发中最重要的活动,也是软件工程中的深水区。往往软件越是庞大挑战程度越高,所需要考虑的问题也需要更全面。而从 4800×4800 矩阵乘法加速效果实测的结果来看,软硬协同将带来万倍代码性能提升。这就是我们为什么一定要做性能调优的原因。
从冯诺伊曼架构来看,影响性能的硬件因素主要有 CPU、内存、网卡和磁盘,因此这些硬件之上的应用是否合理对性能的影响极为关键,也是调优性能的主要方向。
CPU 和内存
CPU 和内存优化的两大方向分别是软加速和硬加速,软加速主要涉及编译优化、NUMA-Aware 亲和性优化。编译器优化主要是针对鲲鹏芯片的微架构,优化了寄存器的分配、指令的部署和流水,提升大部分指令的执行效率。具体来讲,主要分为布局优化、内存布局优化、以及循环优化等;NUMA-Aware 主要是减少内存的跨片和跨 NUMA 访问时产生时延,提高多核架构下面的并行度。此外,硬件加速则是鲲鹏处理器为性能提升提供的一个核武器。
磁盘
因为内存和 CPU 的高速缓存大小都是有限的,我们需要访问的数据大多存在磁盘上或者网络存储上。因此文件系统决定了磁盘加载到内存过程的快慢。华为鲲鹏提供了 EX3、EX14、以及 XFS 等数据访问的管理模式,能够有效提高访问磁盘的性能。
网卡
主要需要根据实际应用场景来调整 frames 和 usecs 两个特性,根据延时和带宽需求来权衡控制两个参数。
应用层
开发者可以提高并发数、优化缓存操作、启用异步读写等,针对鲲鹏平台的系统特性进行整体配置。
在具体的性能调优实践中,第一步就是选择调优方向,包括三大块硬件和应用;第二步是性能采集、分析性能瓶颈、定位热点函数;第三步是针对平台特性充分利用硬件资源;第四步是要在网络端寻求合适的参数平衡点。
鲲鹏应用创新大赛 2020·广州赛区
为了贯彻落实鲲鹏产业生态建设,更好的培育大湾区鲲鹏产业生态,并深入实施信息技术创新战略,广州“鲲鹏 + 昇腾”生态创新中心现计划举办首届“鲲鹏凌粤,展翅湾区”鲲鹏应用创新赛。此次活动以企业开发者为主体,组织鲲鹏赋能培训,并辅以大赛进行成果检验,训赛结合,以训促赛,推进广东地区鲲鹏生态环境的健康发展,提升地区竞争力。
广州赛区共设有“金融”、“政府”、“大数据”、“ARM 原生应用”和“开放命题”5 个赛题,主要面向企业参赛者,广州赛区的奖项激励总额可达 54 万元。各赛题优胜队伍(一等奖)将推选参加“华为开发者大赛 @鲲鹏应用创新大赛 2020”全国赛,全国赛决赛每个赛题将选出 1 支金奖队伍和 2 支银奖队伍。
参赛队伍要取得好成绩,需要注意以下几点:
1、选好作品,解决方案应该足够成熟、应用广泛、有鲜明特色;
2、软件适配鲲鹏平台时要改造彻底,并根据鲲鹏架构做针对性改进和创新;
3、需要准备完整的测试报告,展示报告中要清晰展示方案的架构、功能、价值、前景和优势等要素。
目前,本次比赛的报名渠道已经全面开放,所有的有意参赛者均可在 8 月 15 日前报名并提交作品,
本次【鲲鹏应用创新大赛 2020·广州赛区宣讲会】成功举办,不仅为开发者打造了一个学习软件迁移和调优经验的平台,同时也同步了本次大赛的更多赛事详情,开发者可以通过参与大赛提升实践技能、赢取丰厚大奖。在鲲鹏持续使能开发者、使能合作伙伴的初心下,可以预见,随着鲲鹏产业生态的同行者和共建者越来越多,鲲鹏计算体系生态圈的进一步扩大。





